
Below I attempt to paraphrase the following paper in plain in English: Better Fine Tuning by Reducing Representational Collapse by Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta from Facebook submitted to Arxiv on August 6th, 2020.
tldr
Today NLU is about leveraging pre-trained models on large datasets like RoBERTa and BART and then fine-tuning them for a variety of downstream tasks as described in GLUE, XNLI or text summarization tasks. This paper proposes a new method of fine tuning which is faster and keeps the weights in the model closer to the pre-trained values.

What is Representational Collapse and why does it matter?
In Natural Language Understanding (NLU), the best models are called transformers and were introduced in 2017 by the Google Brain team in their paper (Attention Is All You Need). These models are pre-trained on large amounts of text data like webpages, scientific papers, etc. In a hope to build a more general model, they are then “fine-tuned” on multiple tasks to obtain state-of-the-art (SOTA) performance.
In recent years, emphasis has been placed on how to improve the fine-tuning methods on each task to obtain performance and reduce the computational time spent training the model.
The Problem
When fine-tuning these models a representation of the underlying concepts can effectively overfit to a specific task resulting in worse performance on other tasks. Rather than being able to use the same model across a wide variety of tasks, it is required to adjust the model by retraining on each task. This can be seen in unstable hyperparameter settings where many of them produce poor results. The authors of the paper call this change Representational Collapse or in their words:
Representational collapse is the degradation of generalizable representations of pre-trained models during the fine-tuning stage
The question arises, how do we keep this representational collapse from occurring (or minimize it) to allow for more stable weights across a variety of NLP tasks?
Trust Region Theory
When training a model most often a method called Stochastic Gradient Descent (SGD) is used to move toward the best solution. However, when fine-tuning an already pretrained model this can cause the weights to wander too far from the original values and effectively overfit to the specific task at hand. For example, if a model was pre-trained on dataset A then fine-tuned on dataset B, when it goes to run on dataset C the performance could be suboptimal.
Trust Region Theory suggests that when fine tuning the trained weights should be limited to within a “trusted” region near their original values. This reduces how far the model can wander from the original pre-trained values when being optimized for a downstream task.
Two previous ways of doing this are called SMART and FreeLB which both use an adversarial based approach to limit how far the values can change during the fine tuning stage.
In this paper, the authors propose a new method of fine tuning based on the trust region theory.
R3F and R4F
The authors came up with a simpler approximation method by optimizing for smoothness parameterized by Kullback-Leibler Divergence (KL divergence) and, optionally, further constraining the continuity of the change with a method called Lipschitz continuity. The cool math looks like this…
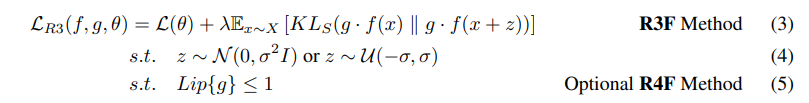
Theta_f are the parameters for some pre-trained representation
Theta_g are the parameters that take input from function f and output a valid probability distribution
L(Theta) denotes the loss function.
R3F stands for Robust Representations through Regularized FinetuningR4F adds the Lipschitz continuity constraint and stands for Robust Representations through Regularized and ReparameterizedFinetuning
Results
Besides being faster to train the R3F and R4F methods performed better on the General Language Understanding Evaluation (GLUE) and tying performance on the cross-language dataset XNLI as well as better on three text summarization datasets: CNN/DailyMail, Gigaword and Reddit TIFU. Figure 2 and Table 2 from their paper show the performance on the GLUE datasets.
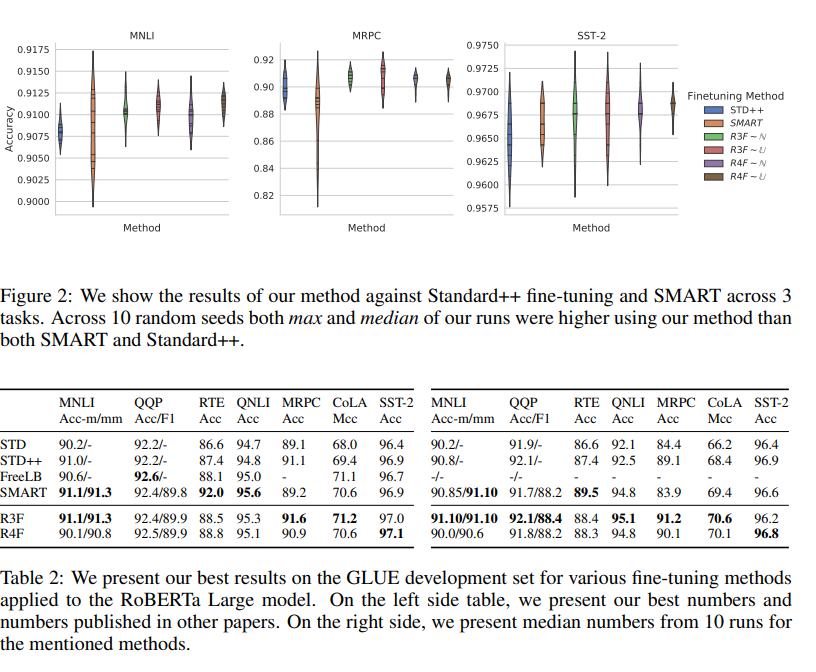
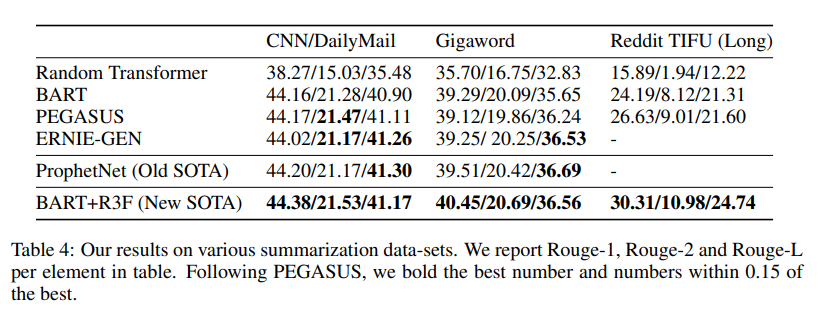
Table 4 shows the performance across the three text summarization datasets.
Measuring Representational Collapse
In addition to achieving state-of-the-art results on many NLP tasks, the authors attempted to verify the Trust Region Theory by estimating the amount of representational collapse (aka how far each fine tuning step moves away from the originally learned representations).
In the first probing experiment, the weights are frozen after the first fine-tuning on the SST-2 task and then a linear layer is added for the other five tasks on the GLUE dataset (MNLI, QNLI, QQP, RTE, MRPC). Figure 3 shows how R3F and R4F methods perform better on two of the tasks compared to SMART and better across all methods compared to the Standard++ method.
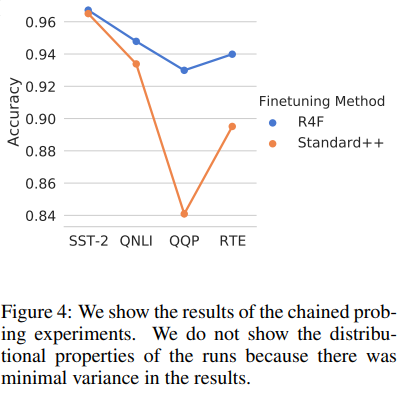
In the second probing experiment, they fine tune the model on a source task (SST-2) and then train on three downstream tasks (QNLI, QQP and RTE). Figure 4 shows how the R4F method outperforms the standard method.
The last probing experiment was done by fine-tuning across three tasks repeated over three cycles. Then the accuracy was compared in each task during each cycle to see how the accuracy improved after repeating the training process. Figure 5 shows the consistent performance improvement for each of the tasks by R4F during each training cycle.
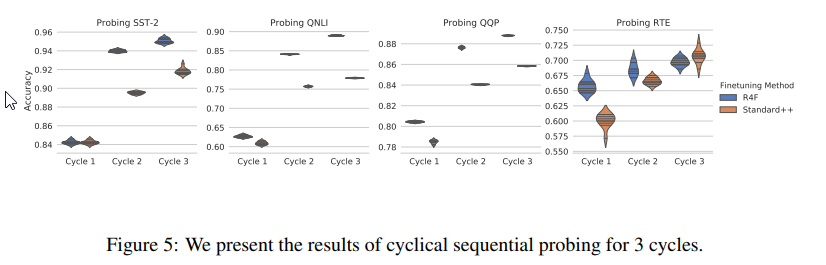
These three probing experiments could be used in future work as an attempt to measure the Representational Collapse during fine tuning.
Conclusion
What is the main takeaway? The field of Natural Language Understanding (NLU) continues to advance by improving the fine-tuning methods of large pre-trained transformers. We’ll likely continue to see optimizations of these types, but will it ever be enough to exceed human level performance on all these tasks?
What is next? Will these fine tuning tasks become a commodity so anyone can easily fine-tune a model for their custom dataset?
How can these NLU tasks be applied in the world of business and help increase productivity?